
Bancos de Dados para Desenvolvedores: SQL e NoSQL em 2026
Como o Instagram consegue carregar seu feed em milissegundos enquanto milhões de outras pessoas fazem o mesmo? Como o Uber coordena motoristas e passageiros em tempo real sem travar? A mágica não está apenas no código do app, mas no coração invisível de toda aplicação moderna: o Banco de Dados.
Em 2026, a fronteira entre o SQL e o NoSQL está mais interessante do que nunca. Não é mais uma competição de "quem ganha", mas um kit de ferramentas onde cada peça tem um propósito cirúrgico. Se você quer entender como armazenar de bytes de texto a terabytes de vídeos com performance, você precisa dominar o alicerce onde os dados vivem. Vamos explorar o cenário atual e descobrir qual motor de dados deve impulsionar sua próxima grande ideia.
Dominar a escolha e o funcionamento desses sistemas é um divisor de águas na carreira de qualquer desenvolvedor. Do rigor do SQL à flexibilidade do NoSQL, entender esses fundamentos é o primeiro passo para construir aplicações que não apenas funcionam, mas que suportam o peso do crescimento real.
O Que São Bancos de Dados?
Um banco de dados é um sistema organizado para armazenar, gerenciar e recuperar informações de forma eficiente. Ele permite que você armazene grandes volumes de dados de maneira estruturada, garantindo integridade, segurança e acesso rápido às informações.
Antes dos bancos de dados modernos, as informações eram armazenadas em arquivos planos, o que tornava difícil manter a consistência, evitar duplicatas e realizar consultas complexas. Com os bancos de dados, é possível:
- Armazenar dados de forma estruturada
- Garantir a integridade dos dados
- Permitir acesso concorrente seguro
- Realizar consultas complexas rapidamente
- Manter backups e recuperação de dados
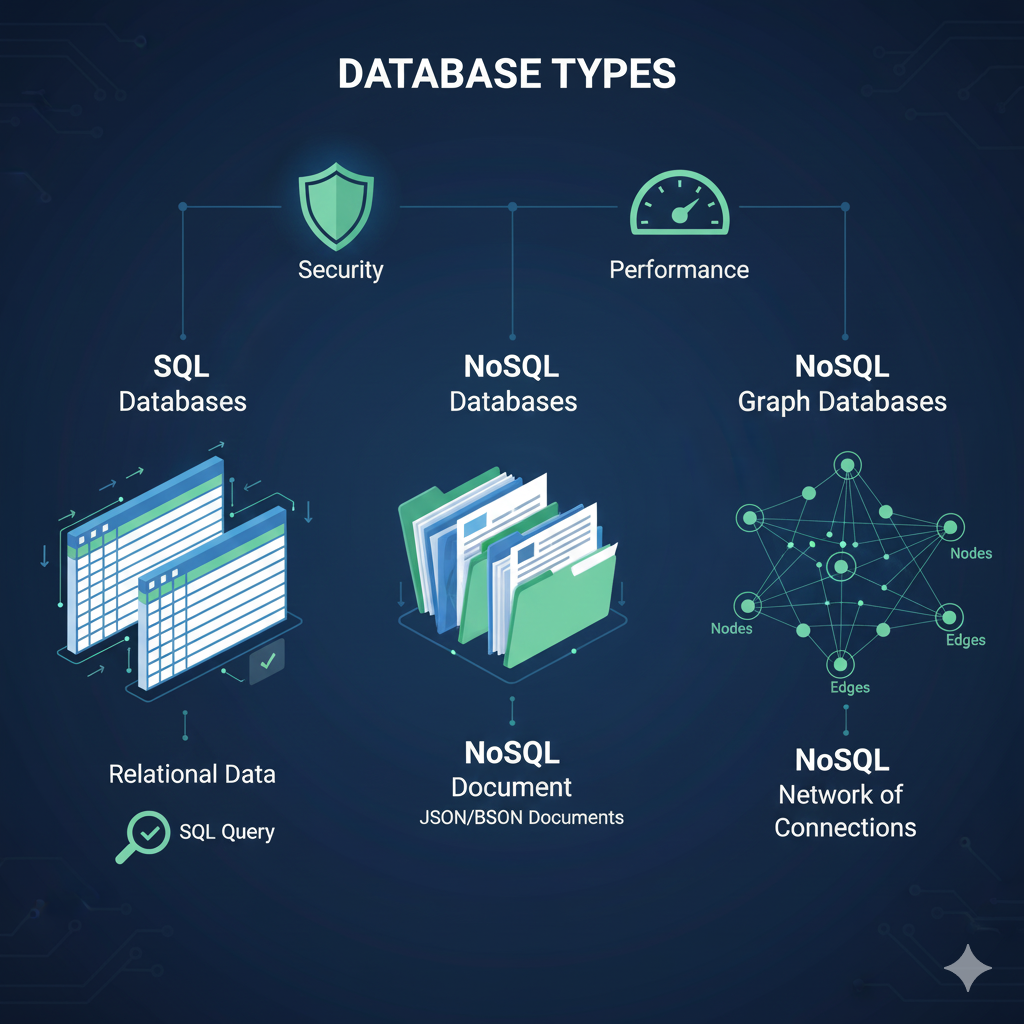
Tipos de Bancos de Dados
Bancos de Dados Relacionais (SQL)
Bancos de dados relacionais armazenam dados em tabelas com linhas e colunas, onde as relações entre os dados são definidas por chaves estrangeiras. Exemplos incluem MySQL, PostgreSQL, SQLite e Oracle.
Vantagens:
- ACID compliance (Atomicidade, Consistência, Isolamento, Durabilidade)
- Esquema bem definido
- Linguagem padrão (SQL)
- Integridade referencial garantida
Desvantagens:
- Escalabilidade vertical (difícil de escalar horizontalmente)
- Esquema rígido
- Performance pode degradar com dados muito complexos
Bancos de Dados Não Relacionais (NoSQL)
Bancos de dados NoSQL oferecem modelos de dados mais flexíveis, como documentos, grafos, pares chave-valor ou colunas. Exemplos incluem MongoDB, Cassandra, Redis e Neo4j.
Vantagens:
- Escalabilidade horizontal
- Flexibilidade de esquema
- Alta performance para operações específicas
- Adequado para big data
Desvantagens:
- Menor consistência (em alguns casos)
- Menos padrões estabelecidos
- Menos suporte para operações complexas
Modelagem de Dados Relacionais
A modelagem de dados é o processo de definir como os dados serão estruturados em um banco de dados. Vamos explorar os conceitos fundamentais:
Entidades e Atributos
Uma entidade é um objeto ou conceito sobre o qual você quer armazenar informações. Um atributo é uma característica da entidade.
Por exemplo, em um sistema de biblioteca:
- Entidade: "Livro"
- Atributos: título, autor, ISBN, ano_publicacao, categoria
Chaves Primárias e Estrangeiras
Uma chave primária é um campo (ou combinação de campos) que identifica unicamente cada registro em uma tabela. Uma chave estrangeira é um campo que faz referência à chave primária de outra tabela, estabelecendo uma relação.
-- Exemplo de criação de tabelas relacionais
CREATE TABLE autores (
id SERIAL PRIMARY KEY,
nome VARCHAR(100) NOT NULL,
nacionalidade VARCHAR(50),
data_nascimento DATE
);
CREATE TABLE livros (
id SERIAL PRIMARY KEY,
titulo VARCHAR(200) NOT NULL,
ano_publicacao INTEGER,
isbn VARCHAR(20),
autor_id INTEGER REFERENCES autores(id)
);
CREATE TABLE usuarios (
id SERIAL PRIMARY KEY,
nome VARCHAR(100) NOT NULL,
email VARCHAR(100) UNIQUE NOT NULL,
data_registro TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE emprestimos (
id SERIAL PRIMARY KEY,
livro_id INTEGER REFERENCES livros(id),
usuario_id INTEGER REFERENCES usuarios(id),
data_emprestimo DATE NOT NULL,
data_devolucao_prevista DATE NOT NULL,
data_devolucao DATE
);Normalização
A normalização é o processo de organizar os dados para reduzir redundância e melhorar a integridade. Existem várias formas normais, mas os conceitos básicos incluem:
- 1FN (Primeira Forma Normal): Eliminar grupos repetidos
- 2FN (Segunda Forma Normal): Eliminar dependências parciais
- 3FN (Terceira Forma Normal): Eliminar dependências transitivas
Linguagem SQL (Structured Query Language)
SQL é a linguagem padrão para gerenciar e manipular bancos de dados relacionais. Vamos explorar os comandos fundamentais:
Consultas Básicas
-- Selecionar todos os registros
SELECT * FROM livros;
-- Selecionar colunas específicas
SELECT titulo, autor_id FROM livros;
-- Selecionar com condições
SELECT * FROM livros WHERE ano_publicacao > 2020;
-- Selecionar com ordenação
SELECT * FROM livros ORDER BY titulo ASC;
-- Limitar resultados
SELECT * FROM livros LIMIT 10;
-- Contar registros
SELECT COUNT(*) FROM livros;Junções (Joins)
Junções permitem combinar dados de múltiplas tabelas:
-- Inner Join
SELECT l.titulo, a.nome AS autor
FROM livros l
INNER JOIN autores a ON l.autor_id = a.id;
-- Left Join
SELECT u.nome, COUNT(e.id) AS total_emprestimos
FROM usuarios u
LEFT JOIN emprestimos e ON u.id = e.usuario_id
GROUP BY u.id, u.nome;
-- Junção com múltiplas tabelas
SELECT l.titulo, a.nome AS autor, e.data_emprestimo
FROM livros l
JOIN autores a ON l.autor_id = a.id
JOIN emprestimos e ON l.id = e.livro_id
JOIN usuarios u ON e.usuario_id = u.id
WHERE u.nome = 'Maria Silva';Funções de Agregação
-- Contar, somar, média, máximo, mínimo
SELECT
COUNT(*) AS total_livros,
AVG(ano_publicacao) AS media_ano,
MAX(ano_publicacao) AS ano_mais_recente,
MIN(ano_publicacao) AS ano_mais_antigo
FROM livros;
-- Agrupar dados
SELECT a.nome, COUNT(l.id) AS total_livros
FROM autores a
LEFT JOIN livros l ON a.id = l.autor_id
GROUP BY a.id, a.nome
HAVING COUNT(l.id) > 0;Inserção, Atualização e Exclusão
-- Inserir dados
INSERT INTO autores (nome, nacionalidade, data_nascimento)
VALUES ('Machado de Assis', 'Brasileira', '1839-06-21');
INSERT INTO livros (titulo, ano_publicacao, isbn, autor_id)
VALUES ('Dom Casmurro', 1899, '978-85-359-1457-2', 1);
-- Atualizar dados
UPDATE livros
SET ano_publicacao = 1900
WHERE titulo = 'Dom Casmurro';
-- Excluir dados
DELETE FROM emprestimos
WHERE data_devolucao IS NOT NULL
AND data_devolucao < '2024-01-01';Bancos de Dados NoSQL
NoSQL oferece modelos de dados alternativos para casos onde SQL não é a melhor opção. Vamos explorar os principais tipos:
Bancos de Dados Documentais (MongoDB)
Armazenam dados em formato de documentos (JSON/BSON), ideais para dados semiestruturados.
// Exemplo com MongoDB
// Inserir um documento
db.livros.insertOne({
titulo: "1984",
autor: "George Orwell",
ano_publicacao: 1949,
genero: ["Ficção", "Distopia"],
avaliacoes: [
{ usuario: "João", nota: 5, comentario: "Excelente livro!" },
{ usuario: "Maria", nota: 4, comentario: "Muito interessante" }
]
});
// Consultar documentos
db.livros.find({ ano_publicacao: { $gt: 1950 } });
// Consulta com projeção
db.livros.find(
{ genero: "Ficção" },
{ titulo: 1, autor: 1, _id: 0 }
);
// Atualizar documento
db.livros.updateOne(
{ titulo: "1984" },
{ $set: { ano_publicacao: 1948 } }
);
// Consulta complexa com operadores
db.livros.find({
$and: [
{ ano_publicacao: { $gte: 1900 } },
{ avaliacoes: { $elemMatch: { nota: { $gte: 4 } } } }
]
});Bancos de Dados Chave-Valor (Redis)
Armazenam dados como pares chave-valor, excelentes para caching e sessões.
import redis
# Conectar ao Redis
r = redis.Redis(host='localhost', port=6379, db=0)
# Operações básicas
r.set('usuario:1', 'João Silva')
r.setex('sessao:abc123', 3600, 'dados_da_sessao') # Expira em 1 hora
# Obter valor
nome = r.get('usuario:1').decode('utf-8')
# Operações com hashes
r.hset('perfil:1', mapping={
'nome': 'João Silva',
'email': 'joao@email.com',
'idade': 30
})
perfil = r.hgetall('perfil:1')
# Listas
r.lpush('fila:emails', 'email1@email.com', 'email2@email.com')
primeiro_email = r.lpop('fila:emails')Índices e Performance
Índices são estruturas de dados que melhoram a velocidade de recuperação de registros. No entanto, eles também afetam o desempenho de inserções e atualizações.
-- Criar índices
CREATE INDEX idx_livros_ano ON livros(ano_publicacao);
CREATE INDEX idx_usuarios_email ON usuarios(email);
CREATE INDEX idx_composto ON emprestimos(usuario_id, livro_id);
-- Índice único
CREATE UNIQUE INDEX idx_livros_isbn ON livros(isbn);
-- Índice parcial
CREATE INDEX idx_livros_recentes ON livros(ano_publicacao)
WHERE ano_publicacao > 2020;Otimização de Consultas
-- Usar EXPLAIN para analisar consultas
EXPLAIN SELECT * FROM livros WHERE ano_publicacao = 2020;
-- Evitar funções em colunas no WHERE
-- Ruim:
SELECT * FROM livros WHERE YEAR(data_registro) = 2026;
-- Bom:
SELECT * FROM livros WHERE data_registro >= '2026-01-01' AND data_registro < '2026-01-01';
-- Usar LIMIT em consultas que podem retornar muitos resultados
SELECT * FROM livros ORDER BY titulo LIMIT 20 OFFSET 40;Transações e Concorrência
Transações garantem que um conjunto de operações seja executado como uma unidade atômica:
-- Transação exemplo
BEGIN;
INSERT INTO emprestimos (livro_id, usuario_id, data_emprestimo, data_devolucao_prevista)
VALUES (1, 1, CURRENT_DATE, CURRENT_DATE + INTERVAL '14 days');
UPDATE livros SET disponivel = FALSE WHERE id = 1;
COMMIT; -- ou ROLLBACK em caso de erroBancos de Dados em Aplicações Modernas
ORM (Object-Relational Mapping)
ORMs permitem trabalhar com bancos de dados usando objetos de programação:
# Exemplo com SQLAlchemy (Python)
from sqlalchemy import create_engine, Column, Integer, String, ForeignKey
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker, relationship
Base = declarative_base()
class Autor(Base):
__tablename__ = 'autores'
id = Column(Integer, primary_key=True)
nome = Column(String(100), nullable=False)
nacionalidade = Column(String(50))
# Relacionamento
livros = relationship("Livro", back_populates="autor")
class Livro(Base):
__tablename__ = 'livros'
id = Column(Integer, primary_key=True)
titulo = Column(String(200), nullable=False)
ano_publicacao = Column(Integer)
isbn = Column(String(20))
# Chave estrangeira
autor_id = Column(Integer, ForeignKey('autores.id'))
autor = relationship("Autor", back_populates="livros")
# Uso
engine = create_engine('sqlite:///biblioteca.db')
Session = sessionmaker(bind=engine)
session = Session()
# Consultas com ORM
autores_com_livros = session.query(Autor).join(Livro).all()
livros_recentes = session.query(Livro).filter(Livro.ano_publicacao > 2020).all()// Exemplo com Mongoose (Node.js + MongoDB)
const mongoose = require('mongoose');
// Definir esquema
const livroSchema = new mongoose.Schema({
titulo: { type: String, required: true },
autor: { type: String, required: true },
ano_publicacao: Number,
generos: [String],
avaliacoes: [{
usuario: String,
nota: Number,
comentario: String
}]
});
// Criar modelo
const Livro = mongoose.model('Livro', livroSchema);
// Operações
async function buscarLivrosRecentes() {
try {
const livros = await Livro.find({ ano_publicacao: { $gte: 2020 } })
.sort({ ano_publicacao: -1 })
.limit(10);
return livros;
} catch (erro) {
console.error('Erro ao buscar livros:', erro);
throw erro;
}
}Casos de Uso Reais
E-commerce
- SQL para transações financeiras (ACID compliance essencial)
- NoSQL para catálogo de produtos e histórico de navegação
Redes Sociais
- Grafos para relacionamentos entre usuários
- NoSQL para feeds de notícias e mensagens
Sistemas Financeiros
- SQL para transações e relatórios (consistência crítica)
- Data warehouses para análise de dados
Jogos Online
- Memória (Redis) para sessões ativas
- SQL para histórico de jogadores e conquistas
Limitações e Desafios
Cada tipo de banco de dados tem suas limitações:
- SQL: Escalabilidade horizontal limitada, esquema rígido
- NoSQL: Menor consistência em alguns casos, menos padrões
- Ambos: Curva de aprendizado, necessidade de otimização contínua
Passo a Passo: Criando um Sistema de Gerenciamento de Dados
Vamos criar um exemplo completo de um sistema de gerenciamento de clientes com SQL:
-- 1. Criar o banco de dados e tabelas
CREATE DATABASE sistema_clientes;
\c sistema_clientes;
-- Tabela de categorias
CREATE TABLE categorias (
id SERIAL PRIMARY KEY,
nome VARCHAR(50) UNIQUE NOT NULL,
descricao TEXT
);
-- Tabela de clientes
CREATE TABLE clientes (
id SERIAL PRIMARY KEY,
nome VARCHAR(100) NOT NULL,
email VARCHAR(100) UNIQUE NOT NULL,
telefone VARCHAR(20),
data_registro TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
categoria_id INTEGER REFERENCES categorias(id),
ativo BOOLEAN DEFAULT TRUE
);
-- Tabela de pedidos
CREATE TABLE pedidos (
id SERIAL PRIMARY KEY,
cliente_id INTEGER REFERENCES clientes(id),
data_pedido DATE NOT NULL,
valor_total DECIMAL(10,2) NOT NULL,
status VARCHAR(20) DEFAULT 'pendente'
);
-- Tabela de itens do pedido
CREATE TABLE itens_pedido (
id SERIAL PRIMARY KEY,
pedido_id INTEGER REFERENCES pedidos(id),
produto_nome VARCHAR(100) NOT NULL,
quantidade INTEGER NOT NULL,
preco_unitario DECIMAL(10,2) NOT NULL
);
-- 2. Criar índices para performance
CREATE INDEX idx_clientes_email ON clientes(email);
CREATE INDEX idx_pedidos_cliente ON pedidos(cliente_id);
CREATE INDEX idx_pedidos_data ON pedidos(data_pedido);
-- 3. Inserir dados de exemplo
INSERT INTO categorias (nome, descricao) VALUES
('Premium', 'Clientes com maior valor de compra'),
('Regular', 'Clientes padrão'),
('Especial', 'Clientes VIP');
INSERT INTO clientes (nome, email, telefone, categoria_id) VALUES
('João Silva', 'joao@email.com', '(11) 99999-9999', 1),
('Maria Santos', 'maria@email.com', '(11) 88888-8888', 2),
('Pedro Oliveira', 'pedro@email.com', '(11) 77777-7777', 3);
-- 4. Consultas úteis
-- Clientes ativos por categoria
SELECT c.nome, cat.nome AS categoria
FROM clientes c
JOIN categorias cat ON c.categoria_id = cat.id
WHERE c.ativo = TRUE;
-- Total de pedidos por cliente
SELECT c.nome, COUNT(p.id) AS total_pedidos, SUM(p.valor_total) AS total_gasto
FROM clientes c
LEFT JOIN pedidos p ON c.id = p.cliente_id
GROUP BY c.id, c.nome
ORDER BY total_gasto DESC;
-- Pedidos recentes
SELECT c.nome, p.data_pedido, p.valor_total, p.status
FROM pedidos p
JOIN clientes c ON p.cliente_id = c.id
WHERE p.data_pedido >= CURRENT_DATE - INTERVAL '30 days'
ORDER BY p.data_pedido DESC;Comparação de Bancos de Dados
| Banco | Tipo | Casos de Uso | Vantagens | Desvantagens | |-------|------|--------------|-----------|--------------| | PostgreSQL | SQL | Aplicações empresariais | ACID, extensões, tipos avançados | Curva de aprendizado | | MySQL | SQL | Web applications | Rápido, ampla adoção | Menos recursos avançados | | MongoDB | NoSQL | Conteúdo dinâmico | Flexibilidade, escalabilidade | Menos consistência | | Redis | NoSQL | Caching, sessões | Alta performance | Volatilidade | | Cassandra | NoSQL | Big Data | Escalabilidade horizontal | Complexidade |
Conclusão
Bancos de dados são fundamentais para qualquer aplicação moderna, e entender as diferenças entre SQL e NoSQL é crucial para escolher a tecnologia certa para seu projeto. SQL oferece consistência e integridade, ideal para transações críticas, enquanto NoSQL oferece flexibilidade e escalabilidade, ideal para dados semiestruturados e alta velocidade.
No momento, a tendência é o uso de múltiplas tecnologias de banco de dados em uma única aplicação (polyglot persistence), escolhendo a ferramenta certa para cada tipo de dado e operação específica. A combinação de SQL para dados transacionais e NoSQL para dados analíticos ou de cache é cada vez mais comum.
Você já trabalhou com diferentes tipos de bancos de dados? Compartilhe sua experiência nos comentários e como escolheu a tecnologia certa para seus projetos.
Glossário Técnico
- SQL: Linguagem de consulta estruturada para bancos de dados relacionais.
- NoSQL: Classe de sistemas de banco de dados que não usam SQL como linguagem principal.
- Chave Primária: Campo único que identifica cada registro em uma tabela.
- Chave Estrangeira: Campo que referencia a chave primária de outra tabela.
- Índice: Estrutura que melhora a velocidade de recuperação de dados.
- Transação: Sequência de operações tratadas como uma unidade única.
- ORM: Técnica que permite interagir com bancos de dados usando objetos de programação.
Referências
- PostgreSQL Documentation. PostgreSQL Tutorial. Documentação oficial do PostgreSQL com tutoriais completos.
- MongoDB University. MongoDB for SQL Developers. Curso comparando SQL e MongoDB.
- W3Schools. SQL Tutorial. Tutorial prático de SQL com exemplos.
